





D2iQ Kaptain enables organizations to develop and deploy machine learning workloads at scale, while satisfying the organization’s security and compliance requirements, thus minimizing operational friction and meeting the needs of all the different teams involved in a successful ML effort.

Feb 24, 2021
Andrew Atkinson
D2iQ

3 min read
AI and Machine Learning (ML) are key priorities for enterprises, with a recent survey showing that 72% of CIOs expect to be heavy or moderate users of the technology. Unfortunately, other research has found that the vast majority—87%—of AI projects never make it into production. And even those that do often take 90 days or more to get there. Why this disconnect between intent and outcome? What are the roadblocks to enterprise ML? And what can be done about them?
There are four major categories of obstacles that impede the enterprise from getting ML models into production:
- First, the technology--especially the cloud native flavor--is relatively novel, with cloud native AI and ML systems only really arising in the last five years.
- Second, this stuff is complex on both the infrastructure and AI/ML tool side, with nearly a thousand different cloud native tools and almost 300 AI/ML tools.
- This complexity is magnified by the issue of integrating these two very large sets: only about 5% of a production ML system is actually the model code, with everything else being the supporting scaffolding handling infrastructure and data issues.
- Finally, for enterprise grade production, there is a need for reliability, scalability, and security, with this last point being a major concern for enterprise IT management.
So, how do you overcome these impediments and achieve the benefits ML offers? With D2iQ Kaptain, which is now generally available!
D2iQ Kaptain is an enterprise-ready end-to-end machine learning platform, powered by Kubeflow, that addresses both structural and organizational challenges and accelerates the time to market and positive ROI by breaking down the barriers between ML prototypes and production. D2iQ Kaptain enables organizations to develop and deploy machine learning workloads at scale, while satisfying the organization’s security and compliance requirements, thus minimizing operational friction and meeting the needs of all the different teams involved in a successful ML effort.
D2iQ Kaptain provides benefits both to data scientists (who have the complexities of the underlying cloud native infrastructure abstracted away) and to platform operations teams, who can quickly and easily offer an end-to-end machine learning platform solution to their data scientist users with all of the reliability, scalability, and security they need in an enterprise grade solution--all based on open source technology, without vendor lock-in.
Built on the robust foundation of the D2iQ Konvoy Kubernetes distribution and incorporating and integrating the best elements of the Kubeflow project, D2iQ Kaptain works anywhere you need to--in the public cloud, on-prem on bare metal or virtual machines, in hybrid environments, even air gapped.
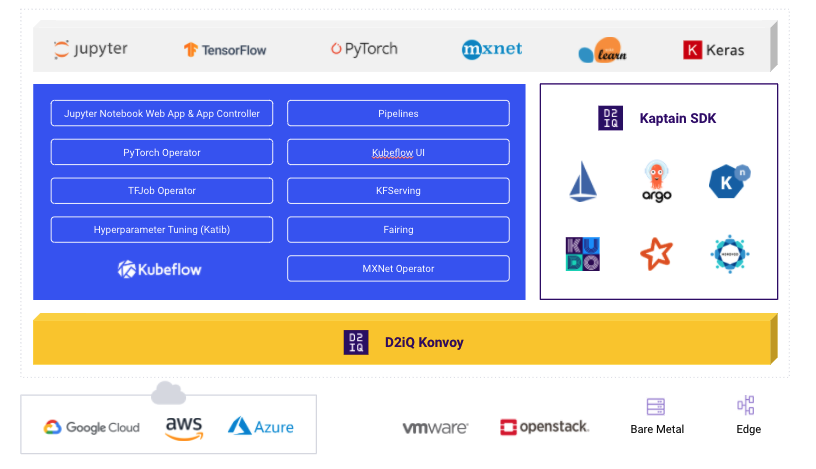
There is so much goodness in Kaptain that it breaks the “there are three things” rule and stretches to four:
- It is built for success, using an integrated, opinionated subset of the Kubeflow project and adding necessary supporting elements such as TensorFlow, PyTorch, and MXNet and out-of-the-box GPU support
- It is notebooks first, to ensure ease-of-use for data scientists--no need for context-switching to get things done; everything can be done from within Jupyter and the Kaptain SDK enables data scientists to make use of entire (not downsampled) datasets and shared GPUs
- It is fast, enabling ML projects to go from prototype to production in minutes, not months with seamless, friction-free deployment
- It takes advantage of the inherent scalability of Kubernetes, with reliable, robust, and autoscaling model deployments as well elastic production infrastructure for training, tuning, and deploying models
If you want to find out more about Kaptain, be sure to register for our upcoming webinar with Kaptain product manager Ian Hellström, himself an experienced data and machine learning engineer. And check out Ian’s two part story about a pack of dogs with an e-commerce dream and a mission-critical ML use-case: AI Chihuahua! Part I and AI Chihuahua! Part II. Then contact us to discuss how you can use Kaptain to break through the ML prototype to production barrier.


