





KIND is a great tool for doing integration tests against Kubernetes. It can launch a fully compliant Kubernetes cluster on your laptop using Docker containers (as nodes) in less than a minute, drastically improving the developer experience when testing against Kubernetes.

May 07, 2020
Jie Yu (github: jieyu)
D2iQ

May 07, 2020
Steven Chung (github: s12chung)
D2iQ

15 min read
We do a lot of testing at D2iQ. Enabling the volume of testing necessary to create enterprise-grade software requires dozens of clusters that are cheap, compliant, and easy to spin up hundreds of times a day.
KIND is a great tool for doing integration tests against Kubernetes. It can launch a fully compliant Kubernetes cluster on your laptop using Docker containers (as nodes) in less than a minute, drastically improving the developer experience when testing against Kubernetes. We’ve been using KIND in various projects internally for a while now.
Internally, many of our projects are using Dispatch (based on Tekton) as the CI tool which runs builds in a production Kubernetes cluster. This choice poses some unique challenges when trying to run a KIND cluster in a Kubernetes pod. While it’s possible, lots of people struggle with doing it. There are quite a few obstacles that we encountered and overcame during this process. In this blog post, we will share those experiences.
Setting up Docker daemon in a Pod
KIND currently depends on Docker (though they have plans to support other container runtimes like podman soon). Thus, the first step is to create a container image that allows you to run Docker daemon inside a Pod, so that commands like `docker run` would work inside the Pod (aka, Docker-in-Docker, or DIND).
Docker-in-Docker is a well known problem and has been pretty much solved for quite a while. Despite that, we still encountered quite a few issues when trying to set up Docker-in-Docker properly in a production Kubernetes cluster.
The MTU problem
The nature of your MTU problem actually depends on the networking provider of your production Kubernetes cluster. The Kubernetes distribution we are using for our CI is Konvoy. Konvoy uses Calico as its default networking provider, and uses IPIP encapsulation by default. IPIP encapsulation incurs a 20-byte overhead. In other words, if the MTU of the main network interface of the host network in the cluster is 1500, the MTU of the network interface in the Pod will be 1480. If your production cluster is running on some cloud providers like GCE, the MTU of the Pod is even lower (1460 - 20 = 1440).
It is important that we configure the MTU of the default Docker network (the --mtu flag of dockerd) inside the Pod so that it is equal to or smaller than the MTU of the network interface of the Pod. Otherwise, you will have connectivity issues with the outside world (e.g. when pulling container images from the internet).
The PID 1 problem
We need to run Docker daemon along with the integration tests, which rely on KIND and Docker daemon, in the same container. A typical way to run multiple services in a container is to use systemd. However, this does not work for our use case due to several reasons:
- We need to preserve the exit status of the tests. Container runtimes used in the Kubernetes cluster (containerd in our case) will watch the exit status of the first process (PID 1) in a container. If we were to use systemd, the exit status of a user test would not be forwarded to Kubernetes.
- For CI builds, getting logs is very important. Kubernetes expects logs of a container to be written to stdout and stderr. If we were to use systemd, we would not be able to get the logs of a user test easily.
As a result, we use a startup script like the following in the container image:
dockerd &# Wait until dockerd is ready.until docker ps >/dev/null 2>&1do echo "Waiting for dockerd..." sleep 1doneexec "$@"
However, there is one caveat here. One simply cannot use the above script as the entrypoint in the container. The entrypoint defined in a container image is run as PID 1 in the container in a separate pid namespace. PID 1 is a special process in the kernel, which behaves differently than other processes.
Essentially, the process receiving the signal is PID 1: it gets special treatment by the kernel; if it hasn't registered a handler for the signal, the kernel won't fall back to default behavior (i.e. killing the process), and nothing happens. A process might not register a signal handler for SIGTERM, thinking that the kernel default behavior would kill the process when SIGTERM is received. If that happens, the SIGTERM will be swallowed when Kubernetes is trying to terminate the Pod, and you will notice that the Pod is stuck in Terminating state.
This is not a new problem, but surprisingly, not many people know about it and keep building containers that have this problem. The solution is to use tini, a small init program that is built for containers, as the entrypoint of the container image like the following in the Dockerfile.
ENTRYPOINT ["/usr/bin/tini", "--", "/entrypoint.sh"]
This program will properly register signal handlers and forward signals. It also performs some other PID 1 things like reaping the zombie processes in the container.
Cgroups mounts
Docker daemon manipulates cgroups, thus it requires the cgroup filesystem to be mounted in the container. Since cgroups are shared with the host, we need to make sure the cgroups manipulated by Docker daemon do not affect other cgroups used by other containers or host processes. We also need to make sure the cgroups created by the Docker daemon in the container do not get leaked after the container is terminated.
Docker daemon exposes a flag --cgroup-parent which tells the daemon to put all container cgroups nested underneath the specified cgroup. When running the container in a Kubernetes cluster, we set the --cgroup-parent flag of the Docker daemon in the container so that all its cgroups are properly nested underneath the cgroup created by Kubernetes for the container.
Historically, to make the cgroup filesystem available in the container, some users bind mount /sys/fs/cgroup from the host to the same location in the container (i.e., using hostPath in Kubernetes similar to -v /sys/fs/cgroup:/sys/fs/cgroup in Docker). If that is the case, you need to set the --cgroup-parent to be the following in the container startup script so that cgroups created by the Docker daemon are properly nested.
CGROUP_PARENT="$(grep systemd /proc/self/cgroup | cut -d: -f3)/docker"
(Note: /proc/self/cgroup shows the cgroup path of the calling process)
As you can tell, bind mounting host /sys/fs/cgroup is pretty dangerous, because it exposes the entire host cgroup hierarchies to the container. To solve this problem in the early days, Docker used a trick to “hide” the irrelevant cgroups from being seen in the container. Docker does a bind mount from the cgroups of the container to the root of the cgroup hierarchy for each cgroup system.
$ docker run --rm debian findmnt -lo source,target -t cgroup SOURCE TARGETcpuset[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/cpusetcpu[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/cpucpuacct[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/cpuacctblkio[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/blkiomemory[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/memory cgroup[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/systemd
As a result, cgroups control files at the root of the cgroup hierarchy inside the container by mapping /sys/fs/cgroup/memory/memory.limit_in_bytes to /sys/fs/cgroup/memory/docker/<CONTAINER_ID>/memory.limit_in_bytes on the host cgroup filesystem. This mapping prevents a container process from accidentally modifying the host cgroups.
However, this trick sometimes confuses programs like cadvisor and kubelet. This is because the bind mount will not change what is inside /proc/<PID>/cgroup.
$ docker run --rm debian cat /proc/1/cgroup 14:name=systemd:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a141 5:memory:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a1414:blkio:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a1413:cpuacct:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a1412:cpu:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a1411:cpuset:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a1410::/
Programs like cadvisor will obtain the cgroup of a given process by looking at /proc/<PID>/cgroup, and try to get cpu/memory statistics from the corresponding cgroup. However, because of the bind mount done by the Docker daemon, cadvisor could not find the corresponding cgroup for container processes. To workaround this problem, we did another bind mount inside the container from /sys/fs/cgroup/memory/ to /sys/fs/cgroup/memory/docker/<CONTAINER_ID>/ (for all cgroup subsystems). This works pretty well in practice. We also upstreamed this workaround to KIND, which has a similar problem.
The modern way to solve this problem is to use cgroup namespaces. Cgroup namespace support has recently been added to runc and docker if you are running on a not too old kernel (Linux 4.6+). However, Kubernetes does not support cgroup namespaces yet at the time of writing, but will soon as part of the cgroups v2 support.
IPtables
We observed that sometimes the nested containers launched by the docker daemon inside the container do not have internet access when running in a production Kubernetes cluster. However, it works perfectly fine on a developer's laptop.
We found that when having this issue, the packets coming from the nested Docker containers are not hitting the POSTROUTING chain in the iptables, thus are not masqueraded properly.
It turns out that the issue was that the container image containing the Docker daemon was based on Debian buster. And by default, Debian buster uses nftables as the default backend for iptables commands. However, Docker itself does not support nftables yet. Although the nftable shim is supposed to be backward compatible with iptables, there are some edge cases that might cause issues, especially on CentOS 7 kernel (3.10), which is used in our production Kubernetes cluster.
To solve this problem, simply switch to the legacy iptables commands in the container image.
RUN update-alternatives --set iptables /usr/sbin/iptables-legacy || true && \ update-alternatives --set ip6tables /usr/sbin/ip6tables-legacy || true && \ update-alternatives --set arptables /usr/sbin/arptables-legacy || true
The full Dockerfile and the startup script can be found here. You can also play with this using this container image jieyu/dind-buster:v0.1.8.
docker run --rm --privileged jieyu/dind-buster:v0.1.8 docker run alpine wget google.com
The same container image can be used in a Kubernetes cluster.
apiVersion: v1kind: Podmetadata: name: dindspec: containers: - image: jieyu/dind-buster:v0.1.8 imagePullPolicy: Always name: dind stdin: true tty: true args: - /bin/bash volumeMounts: - mountPath: /var/lib/docker name: varlibdocker securityContext: privileged: true volumes: - name: varlibdocker emptyDir: {}Running KIND in a Pod
Once we successfully set up Docker-in-Docker (DinD), the next step is to launch the KIND cluster in that container. We tried the following on a laptop, and it worked flawlessly!
$ docker run -ti --rm --privileged jieyu/dind-buster:v0.1.8 /bin/bashWaiting for dockerd...[root@257b543a91a5 /]# curl -Lso ./kind https://kind.sigs.k8s.io/dl/v0.7.0/kind-$(uname)-amd64[root@257b543a91a5 /]# chmod +x ./kind[root@257b543a91a5 /]# mv ./kind /usr/bin/ [root@257b543a91a5 /]# kind create clusterCreating cluster "kind" ... ✓ Ensuring node image (kindest/node:v1.17.0) 🖼 ✓ Preparing nodes 📦 ✓ Writing configuration 📜 ✓ Starting control-plane 🕹️ ✓ Installing CNI 🔌 ✓ Installing StorageClass 💾 Set kubectl context to "kind-kind"You can now use your cluster with:kubectl cluster-info --context kind-kindHave a nice day! 👋[root@257b543a91a5 /]# kubectl get nodesNAME STATUS ROLES AGE VERSIONkind-control-plane Ready master 11m v1.17.0
However, when we try to run this in CI (in the production Kubernetes cluster), things start to fail.
$ kubectl apply -f dind.yaml$ kubectl exec -ti dind /bin/bashroot@dind:/# curl -Lso ./kind https://kind.sigs.k8s.io/dl/v0.7.0/kind-$(uname)-amd64root@dind:/# chmod +x ./kindroot@dind:/# mv ./kind /usr/bin/root@dind:/# kind create clusterCreating cluster "kind" ... ✓ Ensuring node image (kindest/node:v1.17.0) 🖼 ✓ Preparing nodes 📦 ✓ Writing configuration 📜 ✗ Starting control-plane 🕹️ ERROR: failed to create cluster: failed to init node with kubeadm: command "docker exec --privileged kind-control-plane kubeadm init --ignore-preflight-errors=all --config=/kind/kubeadm.conf --skip-token-print --v=6" failed with error: exit status 137
We found that the kubelet running inside the KIND node container (nested) was randomly killing processes in the top level container. Why would that happen? The answer is actually related to the cgroups mounts discussed in the section of that name, above.
When the top level container (the Docker-in-Docker container, aka DIND) is running in a Kubernetes pod, for each cgroup subsystem (e.g. memory), its cgroup path is /kubepods/burstable/<POD_ID>/<DIND_CID> from the host's perspective.
When KIND launches the kubelet inside the nested node container within the DIND container, the kubelet will be manipulating cgroups for its pods under /kubepods/burstable/ relative to the root cgroup of the nested KIND node container. From the host’s perspective, the cgroup path is /kubepods/burstable/<POD_ID>/<DIND_CID>/docker/<KIND_CID>/kubepods/burstable/.
This is all correct, however, you will notice that in the nested KIND node container, there’s another cgroup that exists under /kubepods/burstable/<POD_ID>/<DIND_CID>/docker/<DIND_CID> relative to the root cgroup of the nested KIND node container even before kubelet starts. This is caused by the cgroups mounts workaround we discussed (in the section of that name, above) setup by the KIND entrypoint script. And if you do a cat /kubepods/burstable/<POD_ID>/docker/<DIND_CID>/tasks inside the KIND node container, you will see processes from the DIND container.
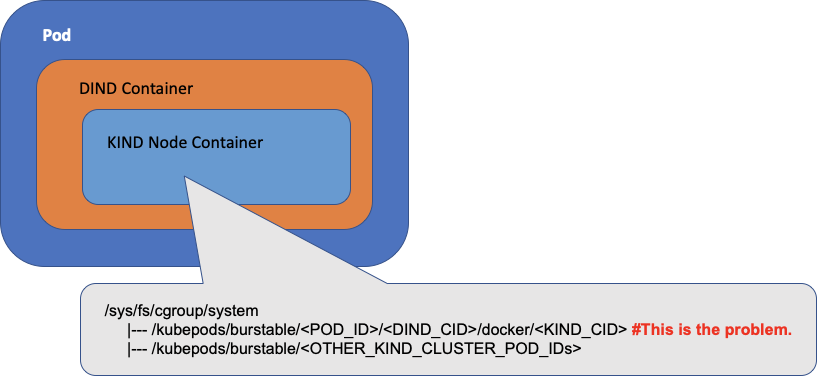
This is the culprit. The kubelet inside the KIND node container saw this cgroup, and thought that it was supposed to be managed by it. But it couldn’t find the Pod associated with this cgroup and responded by trying to remove the cgroup by killing processes belonging to that cgroup. This action results in random processes being killed. The solution to this problem is to instruct the kubelet inside the KIND node container to use a different cgroup root (e.g., /kubelet) for its pods by setting the kubelet flag --cgroup-root.
After that, launching a KIND cluster worked in our production Kubernetes cluster. You can play with that fix by applying the following yaml to your Kubernetes cluster.
apiVersion: v1kind: Podmetadata: name: kind-clusterspec: containers: - image: jieyu/kind-cluster-buster:v0.1.0 imagePullPolicy: Always name: kind-cluster stdin: true tty: true args: - /bin/bash env: - name: API_SERVER_ADDRESS valueFrom: fieldRef: fieldPath: status.podIP volumeMounts: - mountPath: /var/lib/docker name: varlibdocker - mountPath: /lib/modules name: libmodules readOnly: true securityContext: privileged: true ports: - containerPort: 30001 name: api-server-port protocol: TCP readinessProbe: failureThreshold: 15 httpGet: path: /healthz port: api-server-port scheme: HTTPS initialDelaySeconds: 120 periodSeconds: 20 successThreshold: 1 timeoutSeconds: 1 volumes: - name: varlibdocker emptyDir: {} - name: libmodules hostPath: path: /lib/modulesOnce the pod is ready (it will take a minute), exec into the pod to verify.
$ kubectl exec -ti kind-cluster /bin/bash root@kind-cluster:/# kubectl get nodes NAME STATUS ROLES AGE VERSION kind-control-plane Ready master 72s v1.17.0
You could also play with the container directly using Docker CLI:
$ docker run -ti --rm --privileged jieyu/kind-cluster-buster:v0.1.0 /bin/bashWaiting for dockerd...Setting up KIND clusterCreating cluster "kind" ... ✓ Ensuring node image (jieyu/kind-node:v1.17.0) 🖼 ✓ Preparing nodes 📦 ✓ Writing configuration 📜 ✓ Starting control-plane 🕹️ ✓ Installing CNI 🔌 ✓ Installing StorageClass 💾 ✓ Waiting ≤ 15m0s for control-plane = Ready ⏳ • Ready after 31s 💚Set kubectl context to "kind-kind"You can now use your cluster with:kubectl cluster-info --context kind-kindHave a nice day! 👋root@d95fa1302557:/# kubectl get nodesNAME STATUS ROLES AGE VERSIONkind-control-plane Ready master 71s v1.17.0root@d95fa1302557:/#
The full Dockerfile and the startup script can be found here.
Summary
As you can tell, we passed quite a few hurdles during this process. Most of them arose from the fact that Docker container does not provide complete isolation from the host. There are certain kernel resources like cgroups (and many more) that are shared within the kernel, causing potential conflicts if many containers are manipulating them simultaneously.
Once we identified and overcame those hurdles, our solution worked pretty well in production. But this is just a start. We also built several toolings internally around KIND to further improve usability and efficiency, which we will discuss in subsequent blog posts:
- KIND cluster operator for declarative management
- Cluster Claim controller for hot standby clusters
Stay tuned!

