





Kubernetes, Kubeflow, Machine Learning, DKP, Enterprise Kubernetes, AI/ML
D2iQ Kaptain: The Enterprise Machine Learning Platform
The technical preview of D2iQ Kaptain (powered by Kubeflow) is an end-to-end machine learning platform built for security, scale, and speed, that allows enterprises to develop and deploy machine learning models on top of shared resources using the best open-source technologies.

Jul 09, 2020
Ian Hellström
D2iQ

6 min read
Machine learning is the power cable for your business. Without it, your data center is a museum of hard drives. While machine learning can supercharge data-driven businesses, it requires both expertise and a complex suite of technologies to make it work. D2iQ’s Kaptain (originally known as KUDO for Kubeflow) which is in technical preview, is the enterprise platform designed to take you from prototype to production in no time.
Enterprises are expected to store up to 70 billion terabytes in their own data centers within the next five years. If you were to store all that data on slim 5.5 mm (0.22″) hard drives with a 1 TB capacity each, the stack would reach all the way to the moon. If you included data stored on public clouds, the stack would make it to the moon, go around the moon, then back to earth, with almost enough left for a complete trip around the globe. With data volumes growing exponentially, machine learning is no longer an option, but a necessity.
Unfortunately, many enterprises struggle with going from a prototype on a single machine to a scalable deployment. Fewer than 15% of data science initiatives ever reach production, and for those that do, it can take many months to turn a prototype into a production-grade solution.
End-to-end machine learning (ML) platforms for the big data age have only been built at major tech companies in the last decade. That does not mean such infrastructure is out of reach for most companies. In fact, that is why we at D2iQ have built Kaptain: to make world-class machine learning infrastructure accessible to all enterprises.
Our Assumptions
Before we delve into the details of how Kaptain can help enterprises with machine learning, let’s take a moment to review the assumptions that have guided us:
- Enterprises do not see any return on ML investments until the first model has been deployed and validated.
- Enterprises do not have a sustainable return on ML investments unless models are retrained, retuned, and redeployed - regularly and automatically.
- Enterprises demand models to be explainable, reliable, robust, and fair.
- Enterprises cannot scale ML initiatives indefinitely through either hiring and outsourcing, or dedicating expensive hardware to individual users’ machines.
- Enterprises choose their infrastructure (cloud, on-prem, hybrid, edge) based on business requirements, not software limitations.
- Enterprises increasingly rely on open-source technologies for machine learning.
What can we deduce from these assumptions?
Our Commitments
Workflow Automation
Data science as a research organization is a cost center: one-off insights may pay off, but they rarely provide a continuous flow of revenue, and they are often few. Automated deployments are essential to sustained positive returns on ML investments.
Snappy Deployments
Since we tie our success to our customers’ successes, our aim is to make deployments of machine learning models as simple, fast, and reliable as possible.
Model Governance
Regulatory compliance, ethics, and liability of ML-powered solutions imply an increased focus on fairness, reliability, robustness, and interpretability of models. Whereas a few poor recommendations are surely not ideal for an online media service, worst-case performance of models is much more important than the average performance in safety-critical systems (e.g. automotive, aerospace, medical equipment, power plants), many industrial use cases (e.g. chemicals, food processing, manufacturing, mining), and even financial services where incorrect models can negatively affect people’s livelihoods. It is therefore important to have tools to rerun experiments or zoom in on specifics.
Elastic Infrastructure
To scale ML initiatives, organizations must be able to share common infrastructure (e.g. compute and storage), increase productivity and collaboration, and automate as much as possible. This not only means that the infrastructure must be able to scale up/down dynamically, but also that the infrastructure must support the business rather than burden data scientists and engineers alike.
Infrastructure Agnostic
It may sound obvious that businesses decide their infrastructure, but many machine learning tools only play well with specific hardware or in singular public clouds. We don’t believe in technology that “works here, but not there.” In fact, we believe it is important to support air-gapped data centers or even use cases on the edge. If you want to deploy Kaptain in a secure data center without a public internet connection or a mobile research station with slow, intermittent connections in remote locations, that’s your business. Ours is to make it work, anywhere.
Purposeful Simplicity
It is unrealistic to expect data scientists to be experts in statistical modelling, machine learning frameworks, software engineering, data storage solutions, containerization, microservices, networking, orchestration, site reliability engineering, and so on. Whatever responsibilities can be delegated to the infrastructure ought to be. Experts must still be able to tweak configurations, but the typical ML user need not know about load balancers, health checks, IPv6, cluster topologies, and the like.
D2iQ Kaptain
The technical preview of D2iQ Kaptain (powered by Kubeflow) is an end-to-end machine learning platform built for security, scale, and speed, that allows enterprises to develop and deploy machine learning models on top of shared resources using the best open-source technologies. When we say Kaptain is powered by Kubeflow, we mean that some of its core functionality comes from Kubeflow, which is itself a machine learning toolkit that runs on top of Kubernetes. Kaptain also relies upon KUDO, the Universal Declarative Operator; we have used KUDO internally to wire up an opinionated selection of 20+ Kubernetes operators to create Kaptain.
Phew! That’s a lot to take in, so let’s unpack it and answer a few pertinent questions along the way.
End-to-End ML Platform
First, when we say end-to-end, we mean it: data engineering, data science and machine learning, operations, and security. Security is handled by Dex and Istio, who are responsible for authentication, authorization, and end-to-end encryption. Kaptain supports multi-tenancy: fine-grained role-based access controls can be integrated with existing external identity providers, such as LDAP and OAuth.
Second, Kaptain is a platform for machine learning. It has many components that are geared towards development and deployment of machine learning models. Kaptain’s prime focus is not statistical analyses or analytics, although it comes with popular packages, such as Seaborn, statsmodels, SciPy, Keras, scikit-learn, PySpark (for ETL and ML), and NLP libraries: gensim, NLTK, and spaCy. The language of choice is Python, although we support Spark through Scala with Apache Toree, too.
Notebooks-as-a-Service
While setting up a notebook on a single laptop is easy, it becomes tricky as soon as custom libraries are involved, when dealing with drivers while provisioning hardware, or with demands for portability, security profiles, service accounts, credentials, and so on. In short, notebooks are not that simple to manage in an enterprise environment.
Our Jupyter notebooks have everything included to allow data scientists to go from a model prototype to a full-scale deployment with all hyperparameters tuned in a matter of minutes, rather than months. Extensive tutorials show how to use each component of Kaptain — no need to leave Jupyter if you don’t want to!
Fully tested, pre-configured images exist for TensorFlow, PyTorch, and MXNet. All notebook images include Spark and Horovod for distributed training and building data pipelines on the fly. Each image comes in a CPU and GPU flavor, with all the necessary drivers properly configured.
Built-in Best Practices
Kaptain breaks down barriers of productivity with an all-batteries-included platform for development and deployment of machine learning models. There is no need to run prototypes on individual laptops with expensive GPUs in brittle environments. Say goodbye to prototypes that fail on realistic data sets by allowing data scientists to train and tune their models at scale on shared resources without sacrificing security.
Effortless DevOps for ML
The lack of DevOps skills is a significant barrier to adoption of machine learning in the enterprise. Handovers, code rewrites, and delays are not conducive to a collaborative culture that favors fast iterations. But without the tools and specialized knowledge to run models in production at scale, what can data scientists do?
Kaptain gives data scientists tools they are already familiar with to take full ownership of the machine learning life cycle. Models are deployed as auto-scaling web services with pre-configured load balancers, out-of-the-box canary deployments, and monitoring already set up.
Opinionated
The open-source edition of Kubeflow has well over 50 components, integrations, and related initiatives. Underneath it runs Kubernetes with its large ecosystem and steep learning curve. Many of these libraries and frameworks offer similar functionality, which makes life as a data scientist even more confusing. How do you choose from a set of tools you’re not familiar with?
We ensure the best cloud-native tools are included in Kaptain, and only those that provide unique functionality that makes sense for enterprise data science use cases. We research and review alternatives, after which we evaluate each on a set of core criteria, including:
- capabilities vs requirements
- codebase health
- community activity and support
- corporate or institutional backing
- project maturity
- roadmap and vision
- overall popularity and adoption within the industry
We regularly run mixed workloads on large clusters to simulate realistic enterprise environments. That way, the entire stack is guaranteed to work and scale. Each release of Kaptain is also “soaked,” that is, run with a heavy load for a certain duration to validate the performance and stability of the system.
Our tutorials show how to use each of the included components so you do not have to look around for documentation or waste valuable time through trial and error.
What is more, with so many moving parts, a DIY machine learning platform can easily expose your business to unnecessary security risks. In June 2020, ZDNet reported a widespread attack against DIY Kubeflow clusters that failed to implement proper security protocols. Thanks to our enterprise-grade security, Kaptain is protected from such vulnerabilities by design, and is deployed exclusively behind strict authentication and authorization mechanisms.
Kubeflow and Kubernetes
In a similar vein, we opted for Kubeflow, which is the open-source standard for ML on Kubernetes. So, why did we choose Kubernetes?
Kubernetes is the open-source container orchestrator. It provides an abstraction of the underlying infrastructure, which is a natural fit for machine learning. As little as 5% of production machine learning systems comprise the actual code related to the model. A machine learning system also requires notebook servers, metadata storage for lineage and reproducibility, facilities distributed training and parallel hyperparameter tuning, and whatever is needed for deployments, such as model storage, web servers, logging, and monitoring, and much more. To Kubernetes, all of these are “workloads” packed in containers that run on so-called pods. If the number of requests increases, Kubernetes scales up the number of pods in response. If one pod crashes, it spins up another. Storage can be mounted to pods as volumes. Similarly, secrets are managed independently of workloads, without the need to rebuild container images. Many containers can run on the same hardware, all in isolation, so enterprises can best utilize the underlying infrastructure, thus decreasing costs.
Our open-source Kubernetes operators for Kafka and Cassandra (made with KUDO) can be added to Kubernetes clusters for a complete data and machine learning platform: Cassandra, Kafka, Spark, TensorFlow, PyTorch, MXNet, as well as everything you need to distribute training on multiple nodes, tune hyperparameters in parallel, and deploy models that autoscale.
Open Source
The entire Kaptain platform is based on best-of-breed open-source technologies that are curated, integrated, and streamlined by D2iQ. Our commitment to open-source technologies implies we honor APIs. If you want to use only standard SDKs, you can do so with no limitations and without vendor lock-in.
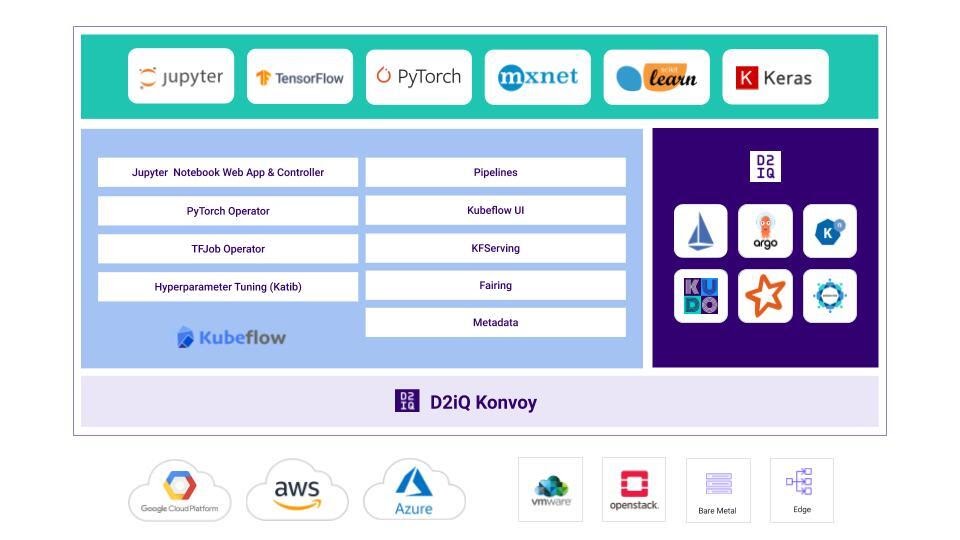
Architecture of Kaptain, which for the technical preview runs on Konvoy.
Day 2 Ready
Kaptain allows enterprises to see the gains of machine learning in no time. Why spend days dealing with installations, setups, and configurations? We offer a two-click installation from Kommander – yes, we counted!
D2iQ offers full support for Kaptain as well as any add-on KUDO operators (e.g. Cassandra and Kafka). That means enterprises enjoy the latest features and novel capabilities with zero downtime.
What’s Next?
For the next release, we shall continue to reduce the time needed to go from prototype to production by improving the user experience with additional operators for idiomatic distributed executions, and adding functionality for data and model management, and end-to-end tracking and monitoring.
In the meantime, sign up for the technical preview of D2iQ’s Kaptain and get ready to power up.

