






May 03, 2017
Amr Abdelrazik
D2iQ

5 min read
DC/OS 1.9 introduced GPU-based scheduling. With GPU-based scheduling, organizations can share resources of clusters for traditional and machine learning workloads, as well as dynamically allocate GPU resources inside those clusters and free them when needed. By using some of the popular libraries for machine learning (such as TensorFlow and Nvidia Docker), data scientists can test locally on their laptops and deploy to production on DC/OS without any change to their applications and models. Read on to learn more about this technology and how you can take advantage of it within Mesosphere DC/OS.
What is a GPU?
The term GPU stands for Graphical Processing Unit. GPUs are different from traditional CPUs such as Intel i5 or i7 processors, which have a smaller number of cores and are designed for general purpose computations. Instead, GPUs are a special type of processor with hundreds or thousands of cores that are optimized for running a large number of computations in parallel. Although GPUs became famous for 3D rendering in games, they are particularly useful for running analytics, deep learning, and machine learning algorithms. GPUs allow certain computations to complete 10X to 100X faster than running the same computations on traditional CPUs. GPU cards (such as NVIDIA's) can be added to most servers and workstations.
Applications that can benefit from GPUs include natural language processing, real-time financial transaction analysis, fraud detection, customer segmentation, shipping route optimization, genome sequencing, and new drug discovery, just to name a few.
GPUs provide two main benefits for machine learning and data intensive applications: speed and efficiency. In terms of speed, computational-heavy machine learning algorithms such as deep learning or random forest can run at a fraction of their usual time on CPUs. This massive advantage in speed unlocks the ability to run more and more complex computations in real time, such as more sophisticated real-time fraud detection, while also dramatically increases the productivity of your data science team.
In terms of efficiency, GPU-enabled nodes are actually orders of magnitude more efficient than traditional CPU-only nodes. Thus, with the added cost of GPU hardware, GPUs provide much cheaper Input/Output Operations Per Second, or to be technically accurate FLoating Point Operations Per Second (FLOPS). Such efficiency reduces the overall number of nodes required for analytics and machine learning, reducing the overall data center or cloud footprint and its associated OpEx or CapEx costs.
Challenges of scheduling GPU workloads
With the rise of machine learning and artificial intelligence, organizations are looking to adopt more GPUs. Unfortunately, three challenges limit such adoption:
Moving Models from Testing to Production
In an ideal world, data scientists would be working on a hybrid cloud model. They would start building the machine learning model on their workstation or laptop, then they would move to testing and training the model on a temporary large scale on-premise or cloud environment infrastructure, before finally moving the trained model to production. Unfortunately, moving between local, cloud, and on-premise infrastructure is a very time-consuming process, since each environment is different in how it is configured, accessed, and managed.
Management Silos
Although they realize more FLOPS/$$$, GPU-enabled clusters are more scarce resources in organizations compared to traditional CPU-only clusters, which means they are often siloed from general purpose workloads. This separation increases the administrative overhead, as administrators need to manage different clusters, migrate and sync data between clusters, and maintain the latest software and drivers.
Efficient Resource Utilization
GPU-enabled clusters are usually dedicated to a specific team or shared across teams. These two scenarios mean that GPUs are either underutilized or overutilized during peak times, leading to increased delays and a waste of precious time for the data science team and cloud resources. Existing tools do not allow dynamic allocation of resources while also guaranteeing performance and isolation.
Introducing GPU Scheduling in DC/OS
Mesosphere has been working with NVIDIA since last year to enable GPU scheduling support in Mesos and DC/OS. Our customers wanted to extend the same benefits of efficiency, resource isolation and dynamic scheduling that were available in Mesos and DC/OS for CPU, memory, and disk resources to GPUs. Our customers also wanted to dynamically scale their machine learning application while maintaining proximity to their data for faster performance while having a unified infrastructure for all their machine learning workloads across any cloud.
DC/OS detects all GPUs on the cluster. GPU-based scheduling allows machine learning applications to request GPU resources similar to CPU, memory, and disk resources, and once those GPU resources are allocated to the app, DC/OS and Mesos resource isolation guarantees that the application has full and dedicated access to those resources, avoiding oversubscription. Applications can then release those GPU resources when done, or scale out to more GPUs that are available.
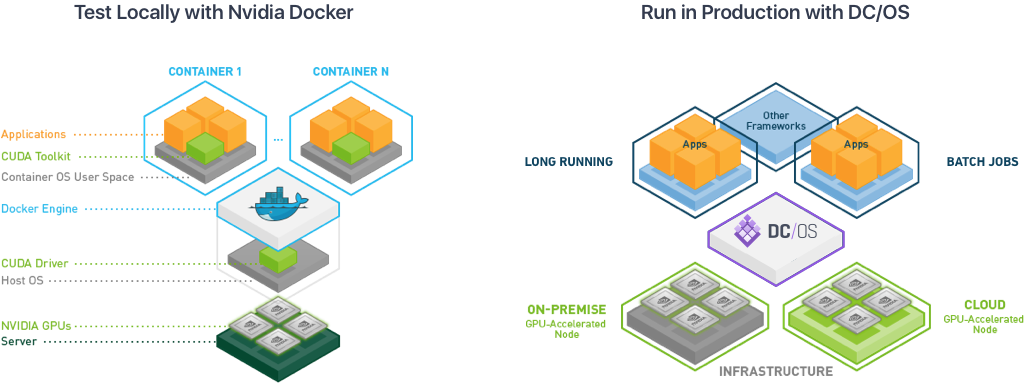
From Laptop to Production DC/OS, CUDA Drivers and Docker
Data scientists can easily use DC/OS, CUDA and Docker to easily move machine learning models from testing to production. CUDA® is a parallel computing platform and programming model invented by NVIDIA. CUDA provides a standard interface to develop applications on top of any NVIDIA-based GPUs independent of the underlying hardware. CUDA is similar to how directX provided applications and gaming developers with a standard library against any graphics processor on Windows operating systems. Docker is a popular file format for packaging and running applications. Many of the machine learning models such as TensorFlow, Caffe, CNTK, etc. are available as Docker containers with the Docker-NVIDIA CUDA driver.
DC/OS eliminates the friction of moving machine learning models from testing to production by using the standard integration libraries for CUDA and Nvidia-Docker. By packaging applications in Docker containers and leveraging the standard Nvidia CUDA libraries, scientists can easily test their models on their laptops and workstations. With few or no modifications, they can then move these models to DC/OS to the cloud or on-premise, where they can leverage more processing power for either testing, training, or just running it continuously next to their applications. This makes it easy to build a temporary GPU-enabled DC/OS clusters on-demand on any of the the cloud providers, enabling data scientists to easily build and train large models large and then shut them down when not needed with minimum cost and effort.
If you would like to learn more, please read our tutorials and documentation.


